Chapter 5 Querying models
Models can be queried using the query_distribution and query_model functions. The difference between these functions is that query_distribution examines a single query and returns a full distribution of draws from the distribution of the estimand (prior or posterior); query_model takes a collection of queries and returns a dataframe with summary statistics on the queries.
The simplest queries ask about causal estimands given particular parameter values and case level data. Here is one surprising result of this form:
5.1 Case level queries
The query_model function takes causal queries and conditions (given) and specifies the parameters to be used. The result is a dataframe which can be displayed as a table.
For a case level query we can make the query given a particular parameter vector, as below:
make_model("X-> M -> Y <- X") %>%
set_restrictions(c(decreasing("X", "M"),
decreasing("M", "Y"),
decreasing("X", "Y"))) %>%
query_model(queries = "Y[X=1]> Y[X=0]",
given = c("X==1 & Y==1",
"X==1 & Y==1 & M==1",
"X==1 & Y==1 & M==0"),
using = c("parameters")) %>%
kable(
caption = "In a monotonic model with flat priors, knowledge
that $M=1$ *reduces* confidence that $X=1$ caused $Y=1$")| Query | Given | Using | mean |
|---|---|---|---|
| Q 1 | X==1 & Y==1 | parameters | 0.615 |
| Q 1 | X==1 & Y==1 & M==1 | parameters | 0.600 |
| Q 1 | X==1 & Y==1 & M==0 | parameters | 0.667 |
This example shows how inferences change given additional data on \(M\) in a monotonic \(X \rightarrow M \rightarrow Y \leftarrow X\) model. Surprisingly observing \(M=1\) reduces beliefs that \(X\) caused \(Y\), the reason being that perhaps \(M\) and not \(X\) was responsible for \(Y=1\).
5.2 Posterior queries
Queries can also draw directly from the posterior distribution provided by stan. In this next example we illustrate the joint distribution of the posterior over causal effects, drawing directly from the posterior dataframe generated by update_model:
data <- fabricate(N = 100, X = complete_ra(N), Y = X)
model <- make_model("X->Y") %>%
set_confound(list(X = "Y[X=1]>Y[X=0]")) %>%
update_model(data, iter = 4000)
model$posterior_distribution %>%
data.frame() %>%
ggplot(aes(X_1.1 - X_1.0, Y.01 - Y.10)) +
geom_point()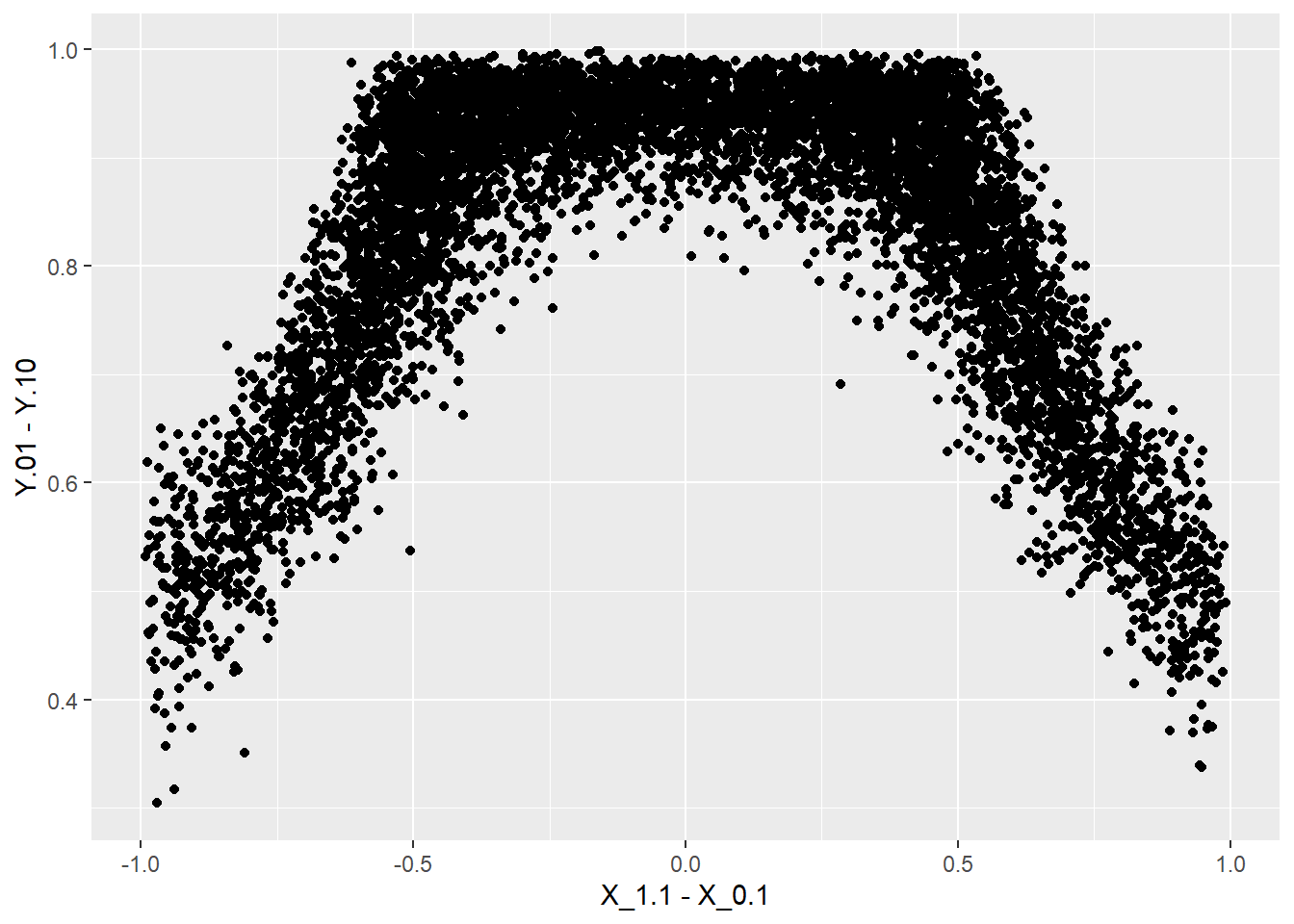
We see that beliefs about the size of the overall effect are related to beliefs that \(X\) is assigned differently when there is a positive effect.
5.3 Query distribution
query_distribution works similarly except that the query is over an estimand. For instance:
make_model("X -> Y") %>%
query_distribution(increasing("X", "Y"), using = "priors") %>%
hist(main = "Prior on Y increasing in X") ## Prior distribution added to model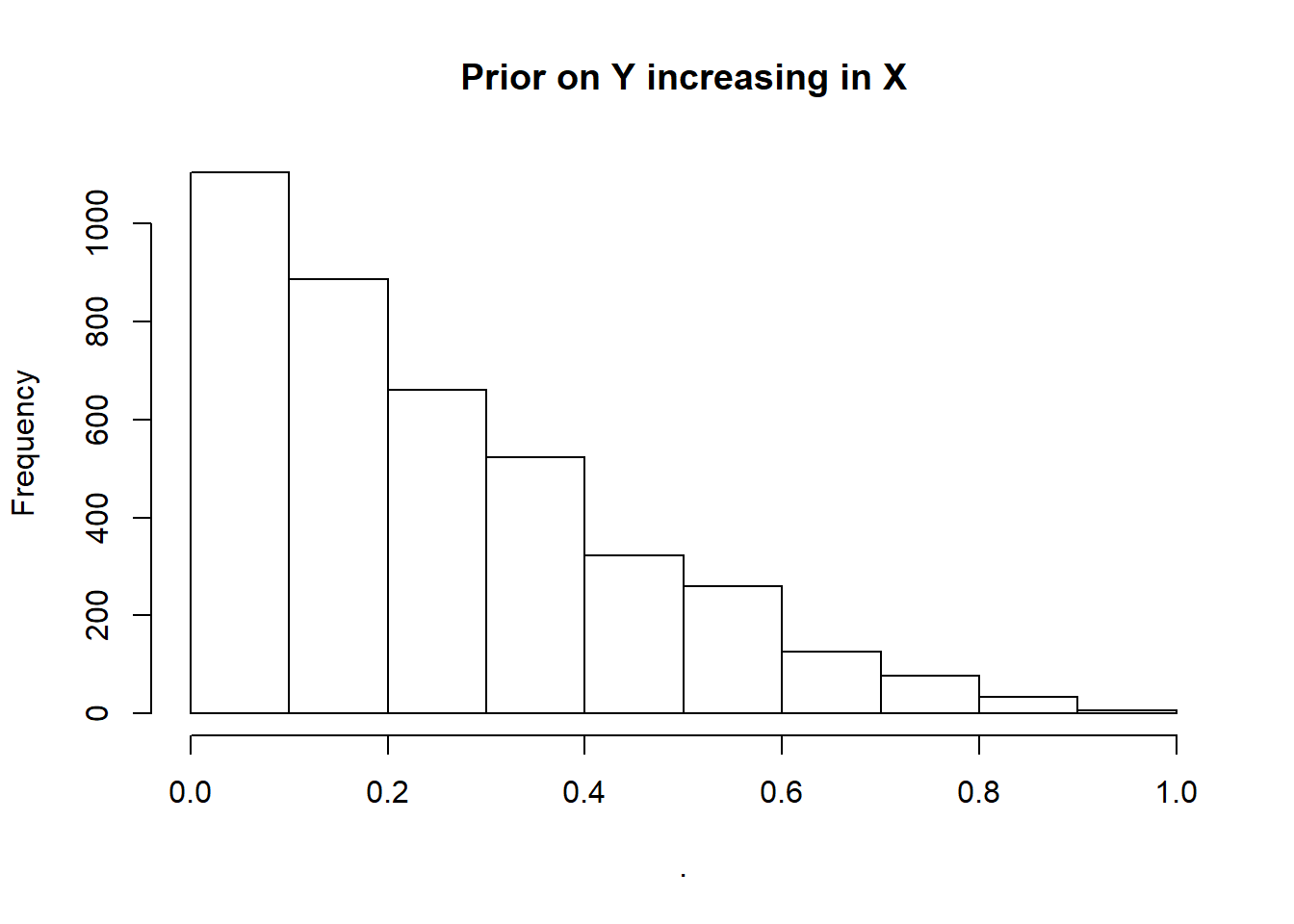
5.4 Token and general causation
Note that in all these cases we use the same technology to make case level and population inferences. Indeed the case level query is just a conditional population query. As an illustration of this imagine we have a model of the form \(X \rightarrow M \rightarrow Y\) and are interested in whether \(X\) caused \(Y\) in a case in which \(M=1\). We answer the question by asking “what would be the probability that \(X\) caused \(Y\) in a case in which \(X=M=Y=1\)?” (line 3 below). This speculative answer is the same answer as we would get were we to ask the same question having updated our model with knowledge that in a particular case, indeed, \(X=M=Y=1\). See below:
model <- make_model("X->M->Y") %>%
set_restrictions(c(decreasing("X", "M"), decreasing("M", "Y"))) %>%
update_model(data = data.frame(X = 1, M = 1, Y = 1), iter = 8000)
query_model(
model,
query = "Y[X=1]> Y[X=0]",
given = c("X==1 & Y==1", "X==1 & Y==1 & M==1"),
using = c("priors", "posteriors"),
expand_grid = TRUE)| Query | Given | Using | mean | sd |
|---|---|---|---|---|
| Q 1 | X==1 & Y==1 | priors | 0.209 | 0.207 |
| Q 1 | X==1 & Y==1 | posteriors | 0.224 | 0.212 |
| Q 1 | X==1 & Y==1 & M==1 | priors | 0.248 | 0.221 |
| Q 1 | X==1 & Y==1 & M==1 | posteriors | 0.252 | 0.221 |
We see the conditional inference is the same using the prior and the posterior distributions.
5.5 Complex queries
The Billy Suzy bottle breaking example illustrates complex queries. See Section 7.2.